Dans les DVD de The IT Crowd (ici la saison 1, qui vaut quelques euros sur Amazon d’occasion), il y a des sous-titres l33t. Et ils cachent dans certains cas des choses intéressantes.
Pour différentes raisons liées à l’époque, les sous-titres des DVD sont particuliers : il ne sont pas enregistrés sous forme de texte. Dans un DVD, les sous-titres sont des images bitmap, sans compression, ce qui – évidemment – rend l’extraction un peu compliquée. La solution de base, schématisée, consiste à récupérer les images puis à passer le tout dans un OCR (quand c’est du texte, ce qui n’est pas obligatoire).

Le menu avec les sous-titres « l33t »
Pour simplifier les choses, sous macOS, j’ai simplement rippé les épisodes en gardant les sous-titres sous forme d’images. Il faut utiliser HandBrake, bien choisir la bonne piste de sous-titres (ici, elle n’a pas de langue) et simplement encoder en décochant les cases Forcés uniquement et Incrustés (Forced only et Burned In en anglais). QuickTime et les outils Apple ne verront pas sous-titres, mais ils sont utilisables avec VLC, par exemple. L’encodage simplifie les choses par rapport à la lecture directe du DVD.
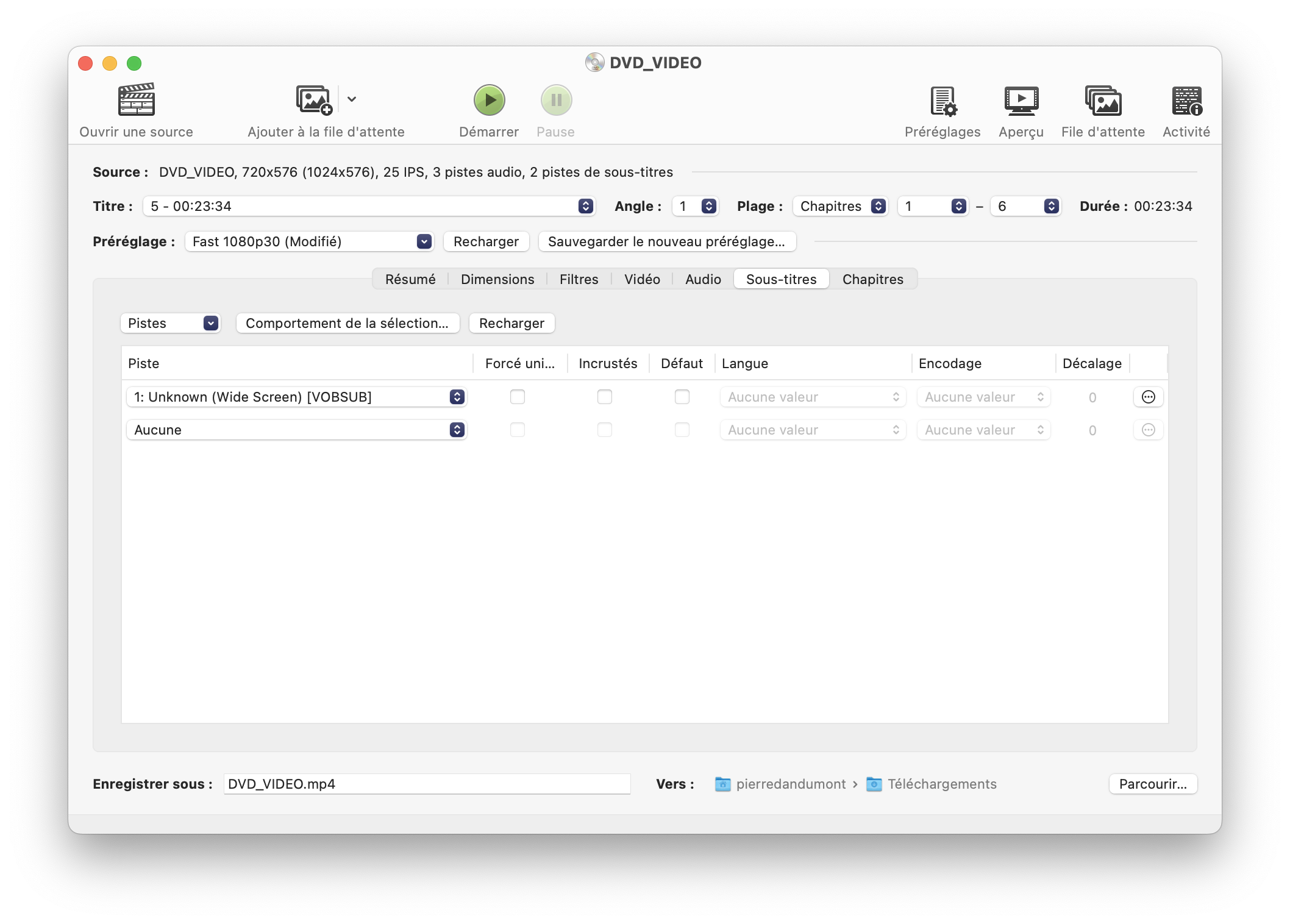
L’encodage et les options
Dans l’épisode 1, on a réellement des sous-titres l33t, qui contiennent des références geek (et nerds, même). Si vous aimez la série, ça peut être amusant à regarder.



Dans l’épisode 2, c’est plus compliqué. On a de vrais sous-titres… mais encodés. C’est du ROT13, un algorithme de chiffrement basique. En ROT13, on décale les lettres de 13 caractères dans l’alphabet, ce qui a l’avantage d’utiliser le même procédé pour encoder et décoder (il y a 26 lettres dans l’alphabet latin). Maintenant, comment décoder les sous-titres ? En utilisant un logiciel qui va lire les images et faire de la reconnaissance de caractères. Sur Mac, j’ai utilisé Subler, un outil vraiment pratique. Il faut ouvrir un nouveau projet, importer le fichier encodé précédemment et cocher uniquement la piste de sous-titres. Ensuite, on peut enregistrer le fichier vidéo, et Subler va utiliser un OCR pour transformer les images en texte. Une fois que c’est fait, on peut même exporter la piste en SRT (un format de sous-titres classique). Avec les sous-titres en ROT13, le résultat est correct et on peut simplement passer le tout dans un décodeur en ligne. Sur le coup, il n’y a rien de spécial : ce sont les sous-titres anglais, a priori sans modifications.
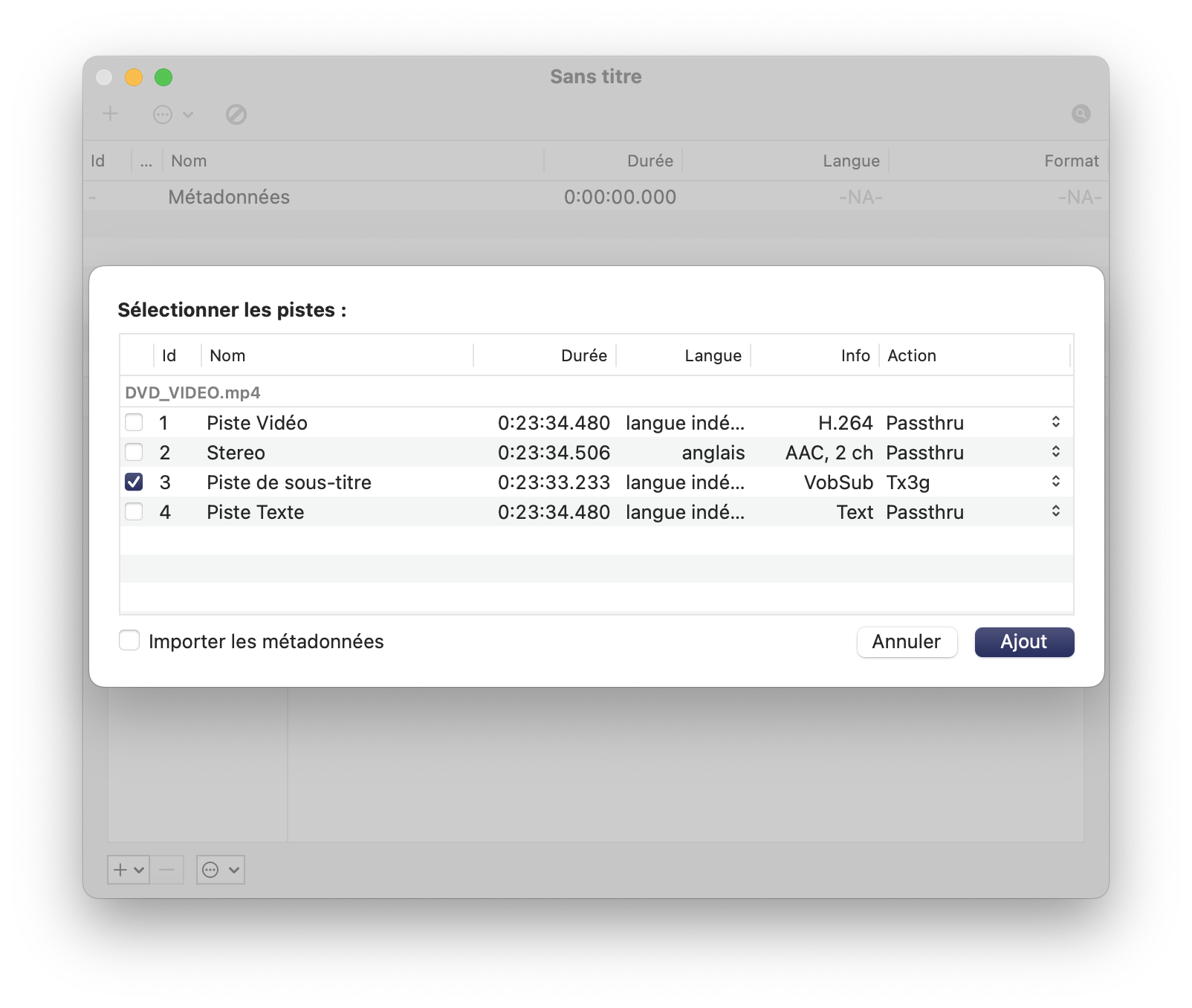
On importe juste les sous-titres

On peut décoder
Pour se donner une idée, voici deux captures.

Do you know one woman
who isn’t obsessed whth shoes?

– You berk!
Come on, are you ready?
Dans l’épisode 3, c’est encore plus idiot. En fait, les sous-titres contiennent tous les mots du script… dans l’ordre alphabétique. Du coup, je n’ai pas extrait le texte : il semble un peu compliqué de tout remettre dans l’ordre.





Dans les épisodes 5 et 6 (je vais parler du 4e plus bas), c’est assez simple : c’357 un3 724n5c21p710n 1337 c14551qu3 d35 73×735 (c’est une transcription l33t classique des textes). Ce sont des sous-titres pour malentendants, donc il y a quelques mots qui décrivent les sons, mais dans l’ensemble c’est compréhensible.

hey. This is fun.
it’s been a good night so far.

I can’t believe he lied like that.

The girl… Oh, my god. The girl, Judy ?

– The toilet cleaners !
– (cheering)

(screams) You’re not listening to me !
I hate when people don’t listen to me !

– U know i do.
– (Phone rings)
Maintenant, l’épisode 4. C’est un peu compliqué : les sous-titres contiennent des données encodées en base64. A l’origine, je n’avais aucune idée du contenu, donc j’ai pensé utiliser la méthode expliquée ici qui parle de la saison 2 de la série. Mais c’est franchement compliqué sous macOS et l’ensemble dépend en réalité d’une distribution GNU/Linux. J’ai donc tenté la méthode expliqué plus haut, avec Subler. Et j’ai eu un problème : ça fonctionne assez mal. Le problème, c’est que l’OCR est prévu pour du texte anglais, donc utilise visiblement un dictionnaire pour décoder. Et comme le base64 n’est pas du texte intelligible, ça fonctionne assez mal. Pour se donner une idée, je vous propose la capture du premier sous-titre, suivi de ce que j’ai extrait avec Subler.
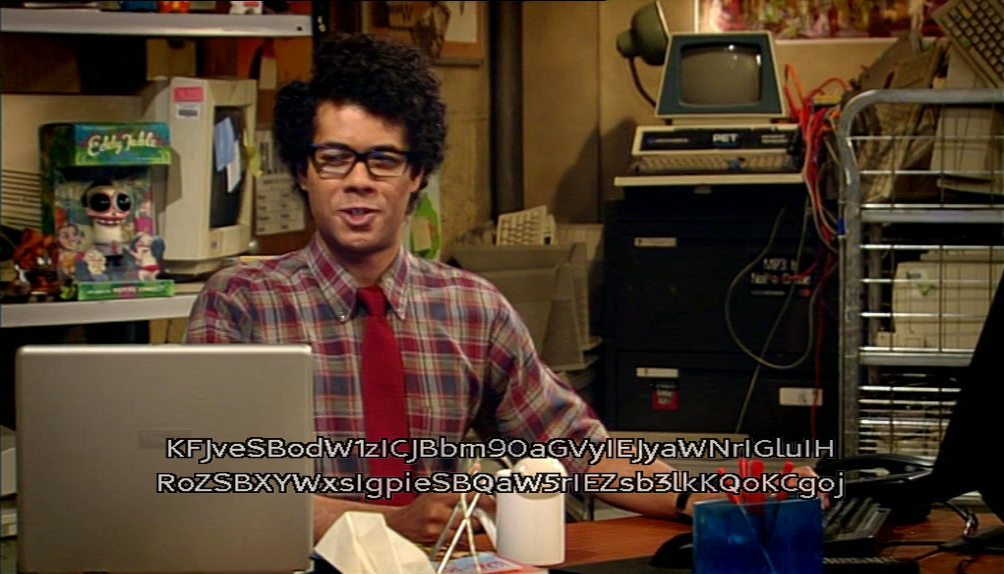
KFJveSBodwizICJBbm90aGVylEJyaWNrlGlulH
RoZSBXYWxslgpieSBQaw5rlEZsb3lkKQoKCgo}
En réalité, je devrais donc avoir ceci (je vous laisse chercher les différences).
KFJveSBodW1zICJBbm90aGVyIEJyaWNrIGlulH
RoZSBXYWxsIgpieSBQaW5rIEZsb3lkKQoKCgoj
Une fois décodé, ça donne ceci :
(Roy hums « Another Brick inthe Wall »
by Pink Floyd)
Du coup, comme pour les épisodes 5 et 6, c’est en réalité le script de l’épisode. En pratique, je n’ai pas décodé la suite, pour une bonne raison : c’est assez fastidieux. Il y a 339 dialogues, avec des erreurs pratiquement dans tous les cas, et c’est difficilement automatisable. Comme le texte est inintelligible et continu, les OCR qui se basent sur un dictionnaire ont vraiment du mal à décoder le texte et même celui intégré dans macOS (si vous avez un Mac récent) n’est pas efficace à 100 %. En utilisant l’image plus haut, j’obtiens par exemple ceci avec macOS.
KFIveSBodwizICJBbm9OaGNylEIyaWNrIGlulH
RoZSBXYWxsigpieSBOaWSTIEzsb3lkKQoKCgoj
Je tenterais peut-être un jour avec les scripts plus haut (sous GNU/Linux), mais pour le moment, j’ai laissé le tout de côté : ça prend vraiment trop de temps pour corriger le résultat de l’OCR. J’ai juste fait le second sous-titre et je vous mets aussi ensuite les deux premières lignes qui donnent évidemment un indice sur l’encodage.

IFdlIGRvbid0IG5lZWQgbm8gZWR1Y2F0aW9uCg
oKClllcywgeW91IGRvLgpZb3UndmUganVzdCB1
We don’t need no education
Yes, you do.
You’ve just u





Excellent, merci !
Puisse ton article faire (re)découvrir à quelques personnes cette série si iconique mais hélas tellement méconnue par rapport à son ersatz américain…
Avec cette série, la découverte de tous les easter eggs présents sur les DVD est un plaisir aussi grand que celui du visionnage des épisodes eux mêmes.
Bon amusement pour le décodage de ceux de la saison 2, car là les fichiers en base64 sont découpés sur plusieurs pages de sous titres…